Most founders I talk to are scoping v1 with two mistakes stacked on top of each other. They’re stuffing it with features nobody asked for, and cutting the foundations the product won’t survive without. The first mistake burns runway. The second burns trust, six months after launch, when their product can’t survive contact with real customers.
This post isn’t a lean startup primer, and it isn’t about validating an idea cheaply before you build. That’s a separate conversation. This one starts after you’ve decided to build: you’ve got a feature list, you’ve got a budget, and you need to know what actually goes in v1.
Scoping isn’t really about cutting features. It’s about deciding what v1 actually needs to do the job, and that includes the invisible parts you’re tempted to skip to ship faster.
Which stage are you at?
Two kinds of founders read this post, and the first question of the filter reads slightly differently for each.
If you haven’t launched yet, v1’s job is learning. You’re trying to find out whether the bet is real. Every feature you keep has to earn its place by teaching you something you couldn’t learn without building it. Everything else is premature.
If you’ve already got signal (a waitlist, a pilot customer, a letter of intent), v1’s job is operating. You’re not validating anymore. You’re running a real business on day one. Every feature has to earn its place by being something the business can’t run without.
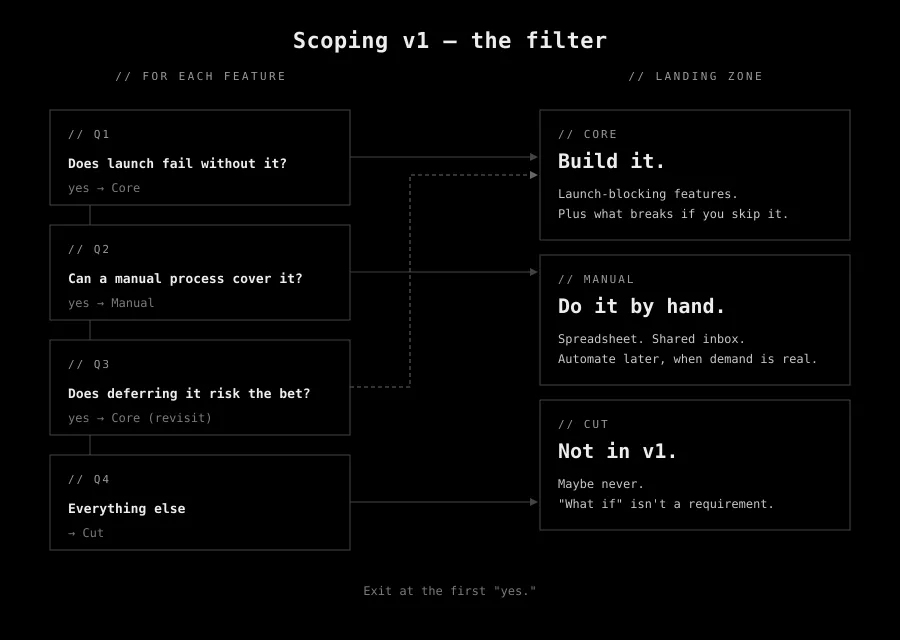
The filter: four questions
Take every feature on the list. Walk it down this ladder. Exit at the first “yes.”
1. Does launch fail without it?
A “yes” means the feature is Core. Build it.
2. Can a manual process cover it for v1?
Be generous with what counts as a manual process.
- A Google Sheet counts.
- A shared inbox where two people manually route things counts.
- A nightly script that emails a CSV counts.
If the workflow can run without the software, even awkwardly, for the first few months, it probably should.
“Yes” means Manual.
3. Does deferring it risk the bet itself?
This is the question that catches the things you’re tempted to skip. Not features, usually. Foundations.
- Deploy automation.
- Error handling that actually surfaces errors.
- Observability (a fancy word for “can we tell what the software is doing when a customer calls us?”).
These don’t show up on feature lists. They’re the first cuts when a deadline gets tight. And for software that goes to paying customers, they’re not optional.
A “yes” here promotes the item back up to Core.
4. Everything else.
If you got here, it’s Cut. Not forever. For v1. Maybe never.
The three buckets
Core.
Launch fails without it. This is the bucket most founders get half right: they fill it with user facing features they’re confident about but forget the foundations that don’t show up in a demo. Deploy automation, error reporting, a way to update the software without driving to the client’s office. That plumbing is Core too, even though nobody ever puts it on a roadmap.
Manual.
The bucket most forget it exists. Do the work by hand on day one. A shared spreadsheet. An inbox. A person who, twice a day, moves rows from A to B.
On day one, you don’t know the shape of the workflow well enough to automate it correctly, and the tools the team already lives in come with zero onboarding and free upgrades when the vendor ships something you didn’t know you needed.
Build the automation later, when demand proves the need.
Cut.
Not in v1.
The honest answer to: “But what if users want X?”
Is usually: “We don’t know yet, and we won’t know until v1 is live.”
It means we’ll revisit with actual evidence instead of speculation.
Diagnostic signals you’re about to over scope
None of these are automatic disqualifiers. They’re signals to look closer.
“Users will expect this.” Speculation framed as requirement. No user has asked. You’re arguing against an imagined objection. The counter-question is cheap: which user? when did they say that?
Admin panels before users exist. Internal tooling for a user base you don’t have yet. A shared doc or a back office hand operation often covers it on day one. You can tell it’s premature when the admin panel has more flows designed than the actual product does.
Billing complexity pre-validation. Stripe Checkout plus one price is day one. Tiers, coupons, annual billing, usage metering, dunning, proration, gift codes: not day one. You can always add tiers later. You can’t get back the six weeks you spent on a pricing page nobody visited.
“What if it goes viral” scaling work. Queues, sharding, caches, microservices for traffic you can’t prove you’ll get. A single modestly sized server handles more than most MVPs ever see. Scale is a problem you earn. Solve it when you earn it.
Copying a competitor’s current product. Their v3 isn’t your v1. Much of what you see is the scar tissue of years of iteration: decisions they couldn’t reverse, migrations they couldn’t afford, compromises stacked on compromises. Copying feature by feature ends up inheriting their constraints more than their insight.
“We’ll need it eventually” enterprise features. SSO, audit logs, role hierarchies, SCIM provisioning. Real needs for enterprise customers, when you have enterprise customers. Until then, every hour spent on them is an hour not spent on the thing that gets you those customers in the first place.
Polish on flows that aren’t validated yet. Animations, empty state illustrations, onboarding tours, dark mode. On features you don’t know anyone wants. Polish makes a working flow feel better. It won’t rescue one that isn’t working yet.
Settings for preferences nobody asked for. Every toggle is a promise you’ll keep both paths working forever. “Maybe some users would want X” is how you end up with a config page that’s bigger than the feature it configures.
Example 1: over building… a paperless menu
A paperless menu startup came out of early 2020, mid-COVID, with a reasonable bet: restaurants would pay for a cleaner experience than handing every table a laminated sheet nobody wanted to touch.
Good instinct. Good timing. Real opportunity. Order at the table from your phone, no waiting for the server, no shared menu.
That was the bet. It’s the only bet they needed to test.
What they built instead was everything.
- Inventory management, because if you know what’s on the menu you might as well know what’s in the kitchen.
- Payments, because if they order from you they should pay through you.
- Delivery logistics, because some restaurants will want delivery and we should be ready.
Each add felt like a reasonable extension of the core. None of them were the core.
Runway kept shrinking. Nothing shipped to a real restaurant. By the time funding tightened, they had a half finished all in one restaurant platform, and the one question that started it all, “will restaurants actually adopt paperless ordering?”, had never been answered, because no restaurant had been given the chance to find out. The company folded before its own v1 was in front of a customer.
Run the features they added through the filter.
- Inventory:
- does launch fail without it? No. Restaurants already manage inventory, usually in whatever system their suppliers push on them.
- Can a manual process cover it? Yes, trivially. It already does.
- Payments: same answer.
- Delivery: same answer.
Every single addition would have exited at Q2. A disciplined v1 would have been the paperless menu, running in one restaurant, for one month, connected to whatever POS the restaurant already used.
Either the bet was real or it wasn’t, and the company would have known, in weeks, for a fraction of what they spent.
Every feature they added was a bet they couldn’t afford to lose. The one bet that mattered never got tested.
And the bet was in fact real, every single sushi restaurant in Italy now uses a similar system.
Example 2: cutting the wrong thing, the environmental sector company
A company building software for the environmental sector shipped fast. The kind of fast you put in a sales deck. They closed deals. They got the product into real customer environments.
Then the real environments started breaking it.
The choice they’d made, explicitly and repeatedly to hit those dates, was to skip the invisible work. Reliable error handling. Telemetry. Install and update automation. The boring plumbing that doesn’t show up in a demo because, when it works, nobody notices it.
The conversation went something like this:
“Should we add this for reliability?”
“We gotta ship.”
“What if it breaks?”
“We’ll test it later. Besides, this kind of software is supposed to run for years with no updates. Once it runs reliably, we’re done.”
“Later” came as a pager, in just a couple weeks.
- A bug at a customer site is corrupting their data: There’s no telemetry to see it remotely, so an engineer gets behind the wheel.
- A critical security update, that was never supposed to be in the first place, needs to roll out fast: No update mechanism exists, so an engineer gets behind the wheel.
The team is now spending most of their engineering capacity on unbillable emergency fixes. They can’t invoice for bugs in a product that was sold as working. New sales have stalled. Partly because the team is too busy putting out fires to close deals, partly because word gets around. They’re shipping cash out the door every month to maintain a product that was supposed to be generating it.
Run error handling through the filter.
- Does launch fail without it? Not visibly, on day one.
- Can a manual process cover it? Weeks and weeks of testing are expensive and not reliable for such things.
- Does deferring it risk the bet itself? Yes.
The bet (that this company could sell software into a sector that depends on reliability) doesn’t survive contact with unreliable software. That’s Q3 catching the cut. The features they shipped were Core. The foundations they skipped were Core too, and skipping them turned the whole product into something that couldn’t do its job.
What they cut was Core. What they should have cut stayed in.
Scope isn’t just features. It’s everything you’d be tempted to skip to ship faster.
Example 3: manual wins, the analytics cronjob
A client I built a small appointment booking app for wanted analytics. You can picture the feature, because I did, immediately: a dashboard. Charts. Date range pickers. Export to CSV. Permissions, so the receptionists see one view and the owner sees another. Easy to spec. Not trivial to build. Definitely not trivial to maintain.
We cut all of it.
What the owner actually needed was to look at weekly numbers and occasionally slice them by month or by practitioner. That’s it. Nothing about that workflow needed a dashboard. It needed numbers, in a place she already checked.
So that’s what it is: a scheduled job, running once a night, writing rows into a Google Sheet she already had open every morning. Filters are whatever Sheets offers. Sharing is already solved, because the sheet is already shared with her accountant. New report? Add a column. New metric? Add a column. The whole thing took an afternoon to build and zero afternoons to maintain.
It’s been years. It’s still what she uses. The Sheet isn’t a compromise. At her scale, it’s genuinely the better tool for the job. A dashboard would have been a second place to check. The Sheet is the first place she already checks.
Through the filter:
- Does launch fail without a dashboard? No.
- Can a manual process cover it? Yes. A cronjob plus a tool she already lives in. Manual bucket. Probably forever.
The right tool was the one she already had open.
This is what the filter is also for. It’s not only about cutting, and it’s not only about protecting foundations. Sometimes it’s about noticing that the best answer to “we need a thing” is “the thing already exists, and it belongs to the client, and all we have to do is get some glue between it and the system.”
The takeaway
Most v1s are smaller than founders think and bigger than founders think.
- Smaller, because the feature list is full of speculation, polish, and scar tissue copied from competitors who are three years ahead of you.
- Bigger, because the foundations you’d skip to ship faster are exactly the ones that decide whether the thing survives first contact with customers.
Scoping an MVP is one job, not two. It’s deciding what v1 needs to work, both technically and product wise. Cut the speculation, protect the foundations, and let everything else wait for a second look.
If you’re staring at a feature list and don’t know what to cut (or what not to cut), I’d be happy to help you sort it.